- A+
所属分类:python
python提取《我修的可能是假仙》
# python提取《我修的可能是假仙》小说
import requests
import re
import time
# from bs4 import BeautifulSoup
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)\
Chrome/59.0.3071.112 Safari/537.36 Vivaldi/1.91.867.48'
}
f = open("我修的可能是假仙.txt", 'a+')
def get_urls():
res = requests.get('https://www.9dxs.com/2/2908/index.html', headers=headers)
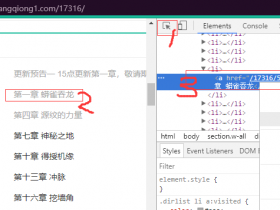
contents=re.findall('<li>.*?<a href="(\d*?.html)">(.*?)</a>.*?</li>', res.content.decode('GBK'), re.S)
for content in contents:
f.write('\n'+content[1] + '\n\n')
print(content[1])
get_info('https://www.9dxs.com/2/2908/{}'.format(content[0]))
time.sleep(0.5)
def get_info(url):
res = requests.get(url, headers=headers)
if res.status_code == 200:
contents = re.findall('<p>(.*?)</p>', res.content.decode('GBK'), re.S)
for content in contents:
content = content.replace(' ', ' ')
content = content.replace('<br /><br />', '\n')
content = content.replace(' ', '')
content = content.replace('<br />', '')
f.write(content+'')
# print(content)
break
else:
pass
get_urls()
f.close()
print("完成")