python UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xe7 UnicodeDecodeError: 'ascii' codec can't decode byte 0xe7 问题描述: python进行字符串操作时,出现以下报错: UnicodeDecodeE... 07月17日 热度7,264 度 发表评论 阅读全文
python python3爬取小说《假装自己是学霸》 最近在QQ阅读看《我的徒弟都是大反派》和《假装自己是学霸》。由于第二本刚看不久,而第70章之后收费,算了下第二本的阅读成本有点小贵,就只好暂时告别正版了😓。下面就演示如何python3提取小说到txt... 05月19日 热度8,721 度 发表评论 阅读全文
python python3提取小说《我修的可能是假仙》 python提取《我修的可能是假仙》 # python提取《我修的可能是假仙》小说 import requests import re import time # from bs4 import Be... 04月28日 热度8,238 度 发表评论 阅读全文
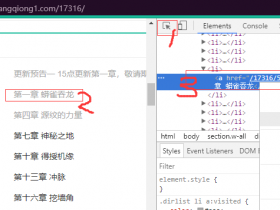
python python爬取小说《元尊》 python爬取小说《元尊》 《元尊》是天蚕土豆的新连载小说。为了方便阅读,下面将会演示提取http://doupocangqiong1.com/17316/ 站点中《元尊》 目前所有章节并整合到tx... 04月18日 热度6,449 度 发表评论 阅读全文
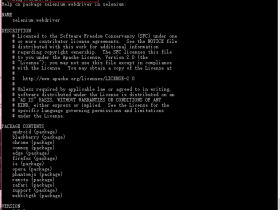
python Selenium和PhantomJS Selenium模拟浏览器 在进行爬虫的时候,对于采用了异步加载技术的网页,有时候通过逆向工程进行爬虫构造是比较困难的。这个时候我们可以使用Selenium模块模拟浏览器的各种操作,来达到获取我们所需... 03月04日 热度8,463 度 发表评论 阅读全文
python 爬虫三大库简介 爬虫三大库简介 Requests库 Requests库官方文档链接:http://docs.python-requests.org/zh_CN/latest/ Requests: 让 HTTP 服务人... 02月27日 热度7,866 度 发表评论 阅读全文
 python
python
 python
python
 python
python
python
python
 python
python
 python
python
 python
python
